We provide complete services for Machine Learning Services
From data collection, preprocessing, quality control to transcription factor binding sites, histone modifications and much more.
Providing services to
worldwide clients
Datasets
analyzed
Qualified researchers and
Bioinformatics analysts
Satisfied orders processed
Our Services
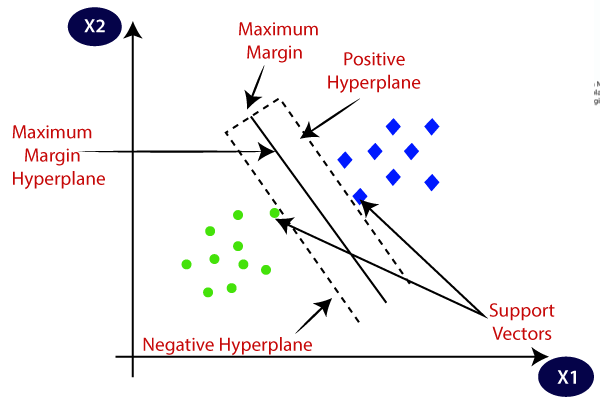
- Use of support vector machine(SVM) algorithm that works on gene expression data type to classify cancer vs healthy.
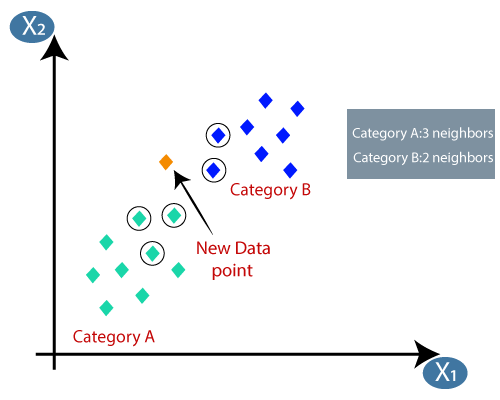
- Use of k-nearest neighbors(KNN) algorithm that works on gene expression data type to classify multiclass tissue.
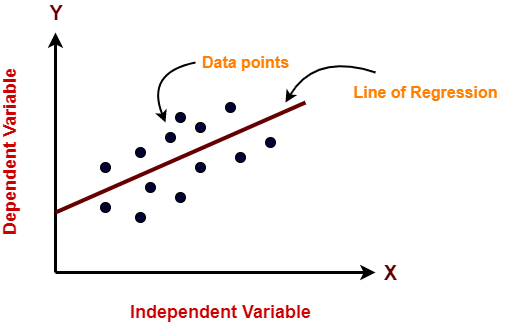
- Use of the regression algorithm that works on SNP(Single nucleotide polymorphisms) data type to analyze a genome-wide association.
- Use of convolutional neural networks (CNN) works on amino acid sequence data type to predict protein secondary structure.
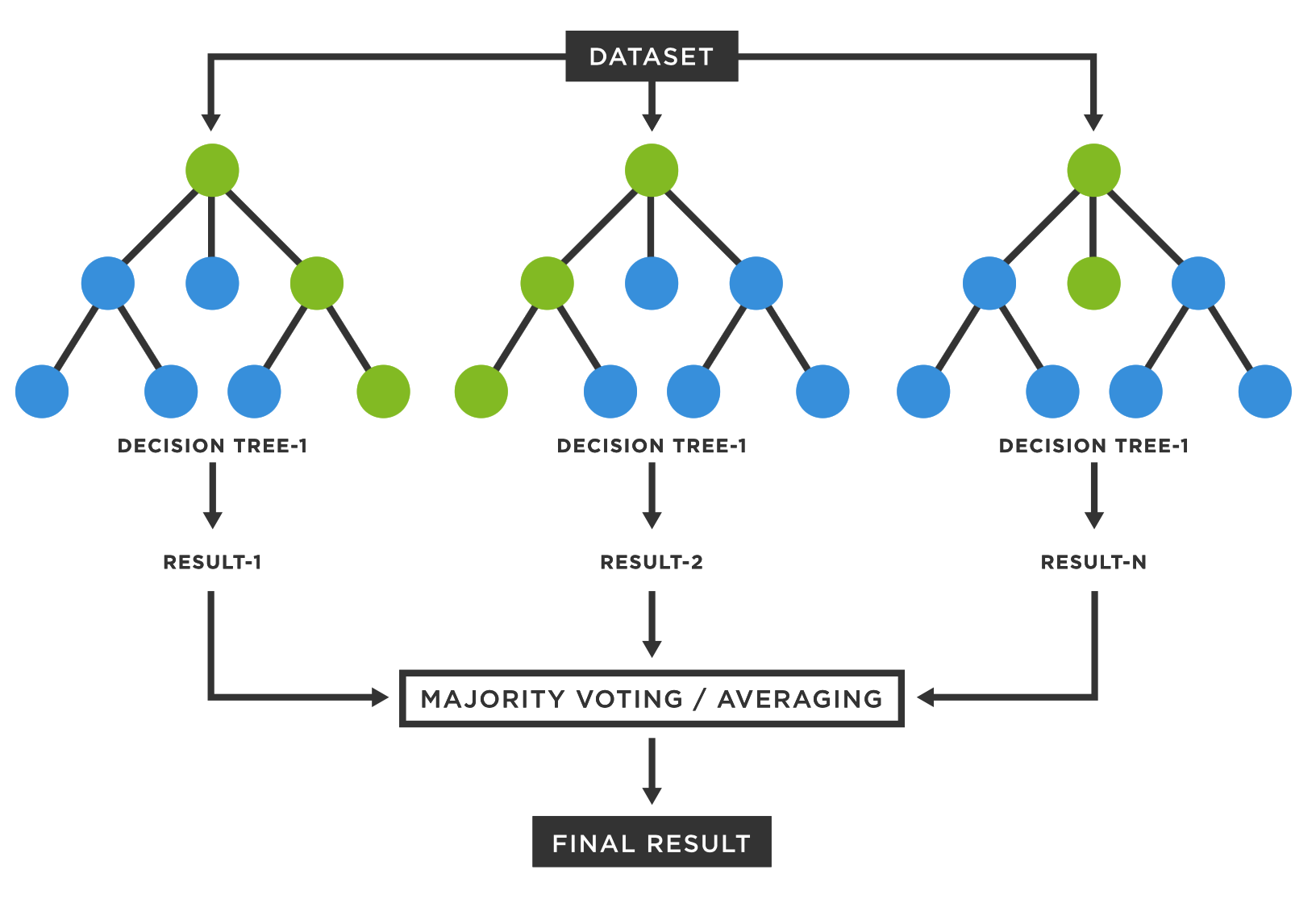
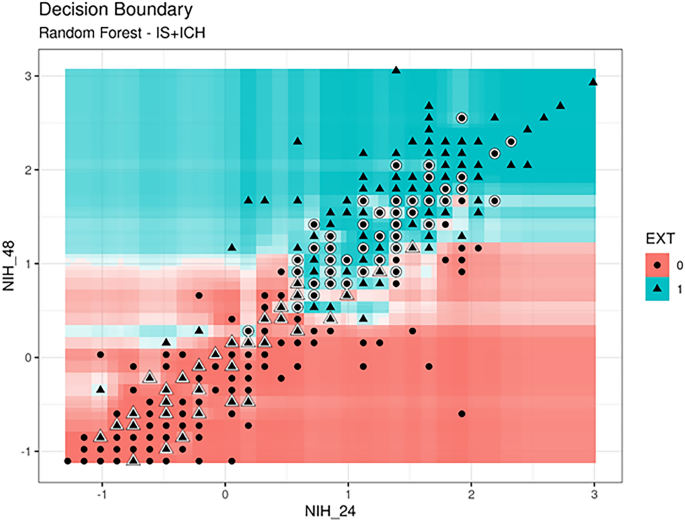
- Use of random forest algorithm that works on gene expression and SNP data type for pathway-based classification.
- Use of Recurrent neural networks (RNN) algorithm that works on nucleotide sequences to predict sequence similarity.
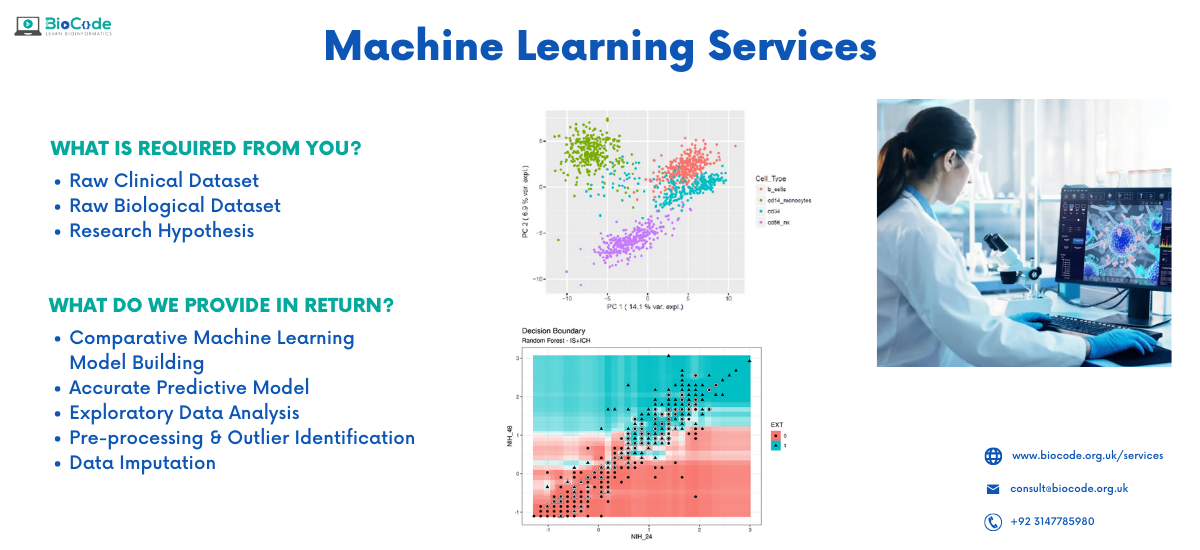
- Use of Principal component analysis (PCA) algorithm that works on gene expression data type to classify outliers.
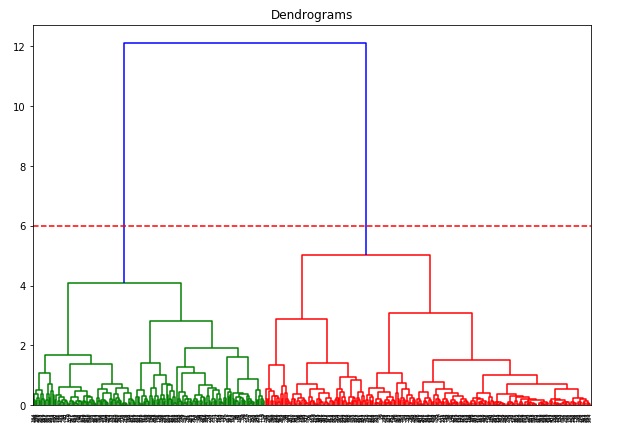
- Use of hierarchical clustering algorithm that works on amino acid sequence data type to cluster protein families.
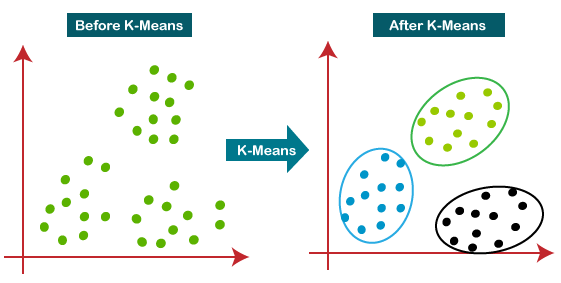
- Use of k-means algorithm that works on gene expression data type for clustering genes by chromosomes.
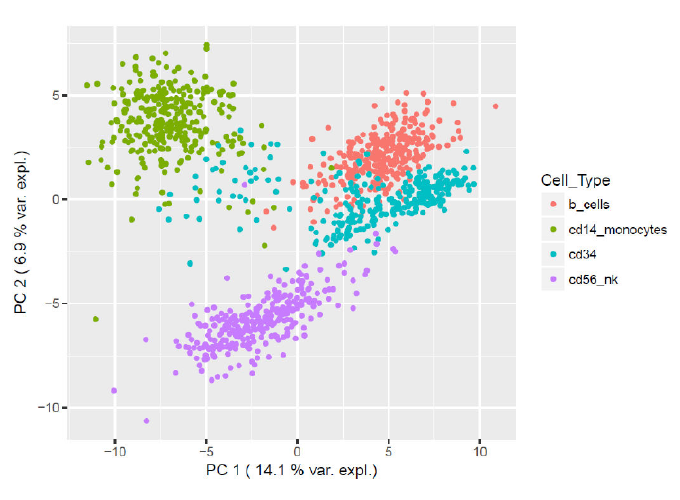
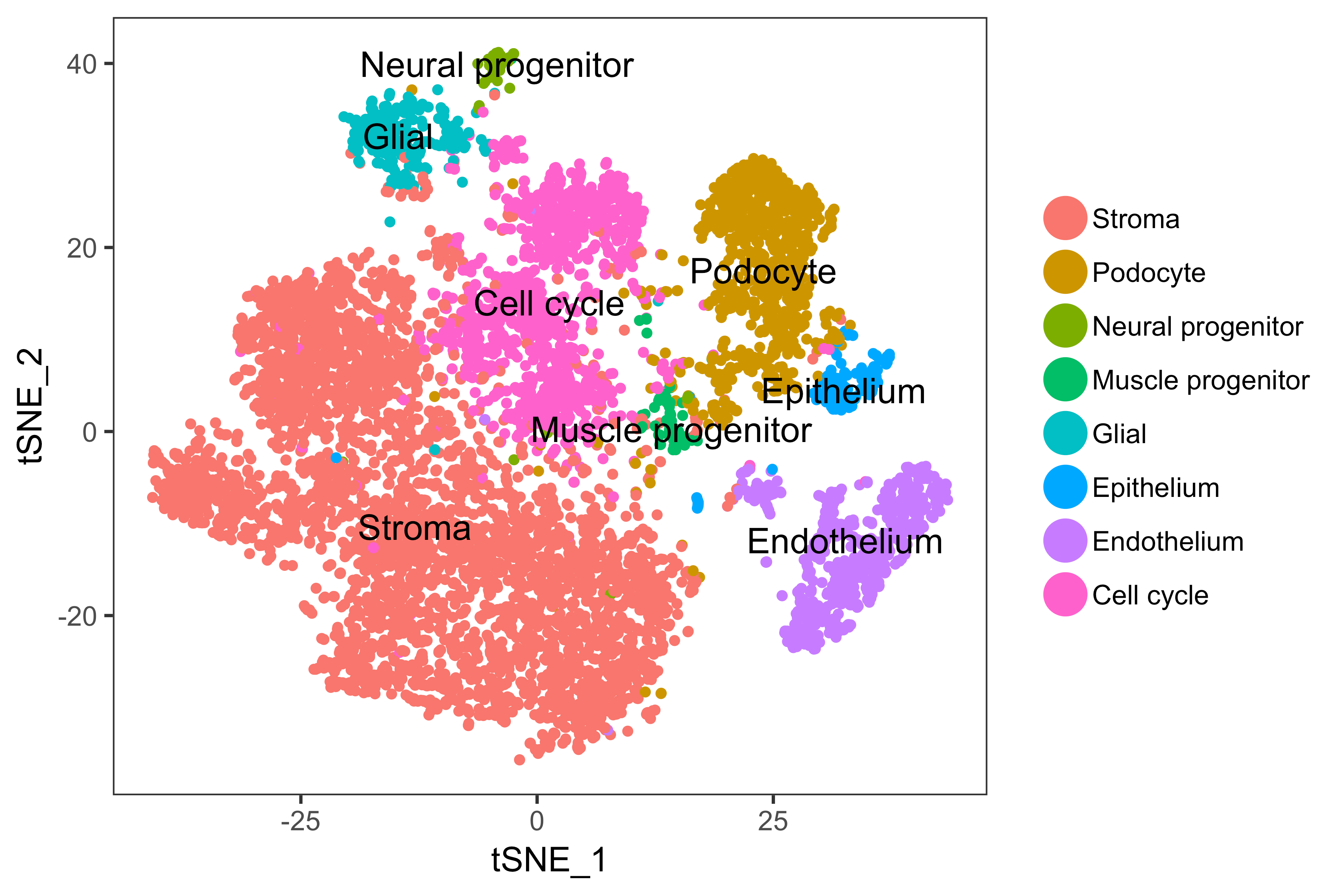
- Use of t-distributed stochastic neighbour embedding (tSNE) algorithm that works on single-cell RNA-sequencing for data visualization.
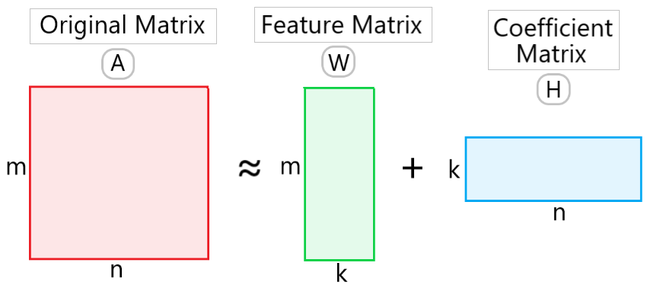
- Use of Non-negative matrix factorization (NMF or NNMF) algorithm that works on gene expression data type to cluster gene expression profiles.
- Use of random forest regression model and extreme gradient boosting (XGB) model to evaluate protein descriptors in computer-aided rational protein engineering tasks.
- Use of Data mining to identify large scale bio-molecular interactions; Protein-protein interactions, Protein-DNA interactions.
- Use of Deep Learning for dimension reduction in single-cell gene expression data.
- Use of deepMNN, a novel deep learning based method to correct batch effect in scRNA-seq data using mutual nearest neighbors.
- Use of SCVIS neural networks model for cell-type identification from single-cell transcriptomics data.
- Use of multiple machine learning models to produce RNA-binding proteins, transcription factors, predicting and classifying gene expression.
- Use of deep learning model called DeepLoc to classify mutations and protein subcellular localization.
- Use of multiple machine learning algorithms to perform gene editing depending on the task.
- Use of NLP(Natural Language Processing) in ML to access patient data efficiently with electronic medical records.
- Use of text mining algorithms to search biological databases because of the increase in biological publications has made it difficult for researchers.
- Identification of transcription binding sites by the use of a technique called Markov chain optimization.
- Figuring out the structure between different variables and modeling genetic networks using probabilistic graphical models.
- Using genetic algorithms to model genetic networks and regulatory structures.
- Use of random forest, naive bayesian and support vector machine in drug discovery processes including precision medicine and next-generation sequencing.
- Using DNN, logistic regression, random forest to predict motor deficits in stroke patients.
- Identification of promoters in DNA sequences using multiple machine learning algorithms.
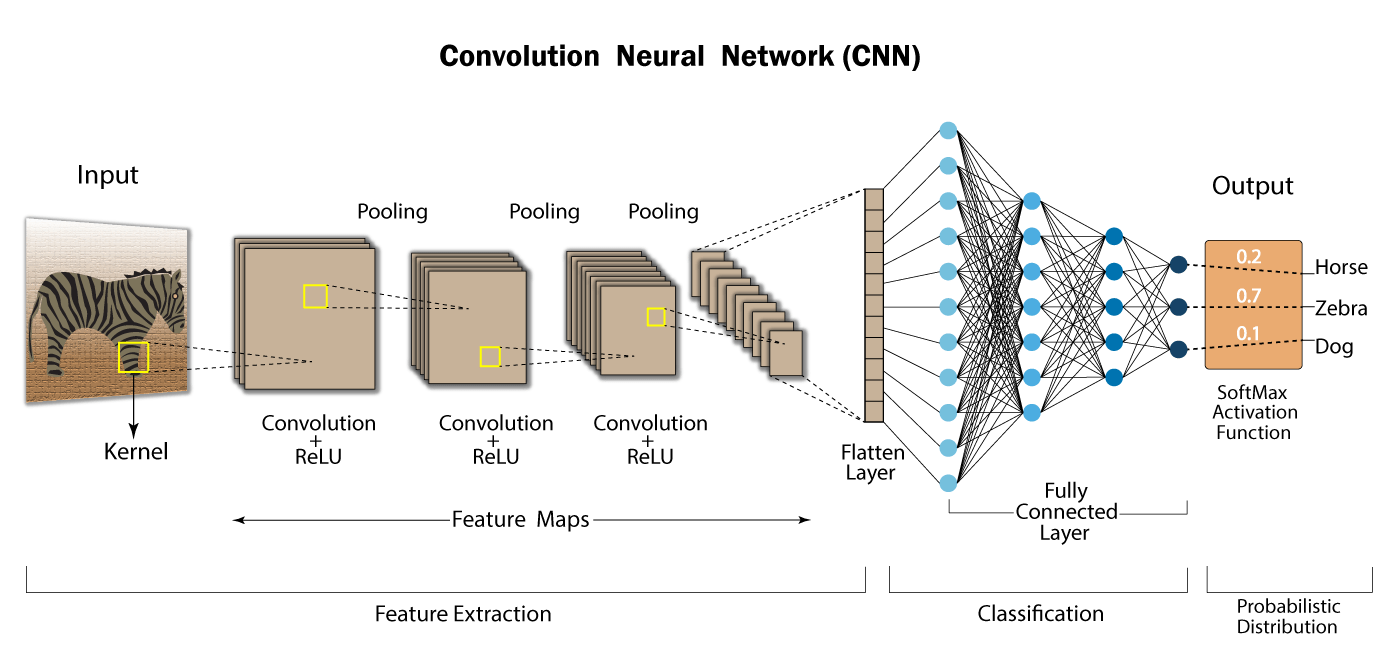
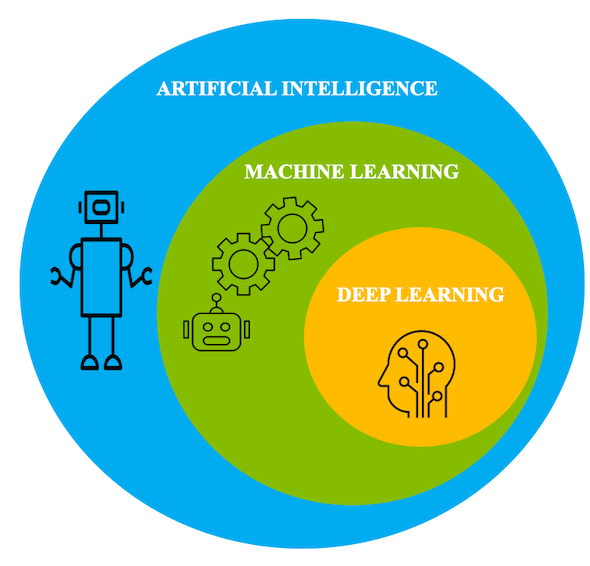
Machine learning is a branch of artificial intelligence (AI) based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention. The major contribution of AI in bioinformatics analyses depends on pattern matching and knowledge based learning systems to solve the biological problems.
Before machine learning emerged, bioinformatics and other biological fields faced the problem of extracting valuable insights from large biological datasets. But as of today, ML techniques such as deep learning can learn the features of complex datasets and present them in a manner that is easy to understand. Machine learning has multiple applications in diverse fields, ranging from natural language processing to healthcare. Machine learning in bioinformatics is the application of machine learning algorithms in bioinformatics; genomics, proteomics, microarrays, systems biology, evolution, and text mining. It serves as an advanced tool in the bioinformatics area which deals with molecular phenotypes, drug discovery, and aids in determining unfamiliar diseases etc.
It’s a machine-learning algorithm that extracts high-level features from raw input by imitating how the human brain works. Deep learning is used in drug discovery, de novo molecular design, sequence analysis, protein structure prediction, gene expression regulation, protein classification, biomedical image processing and diagnosis, biomolecule interaction prediction etc.
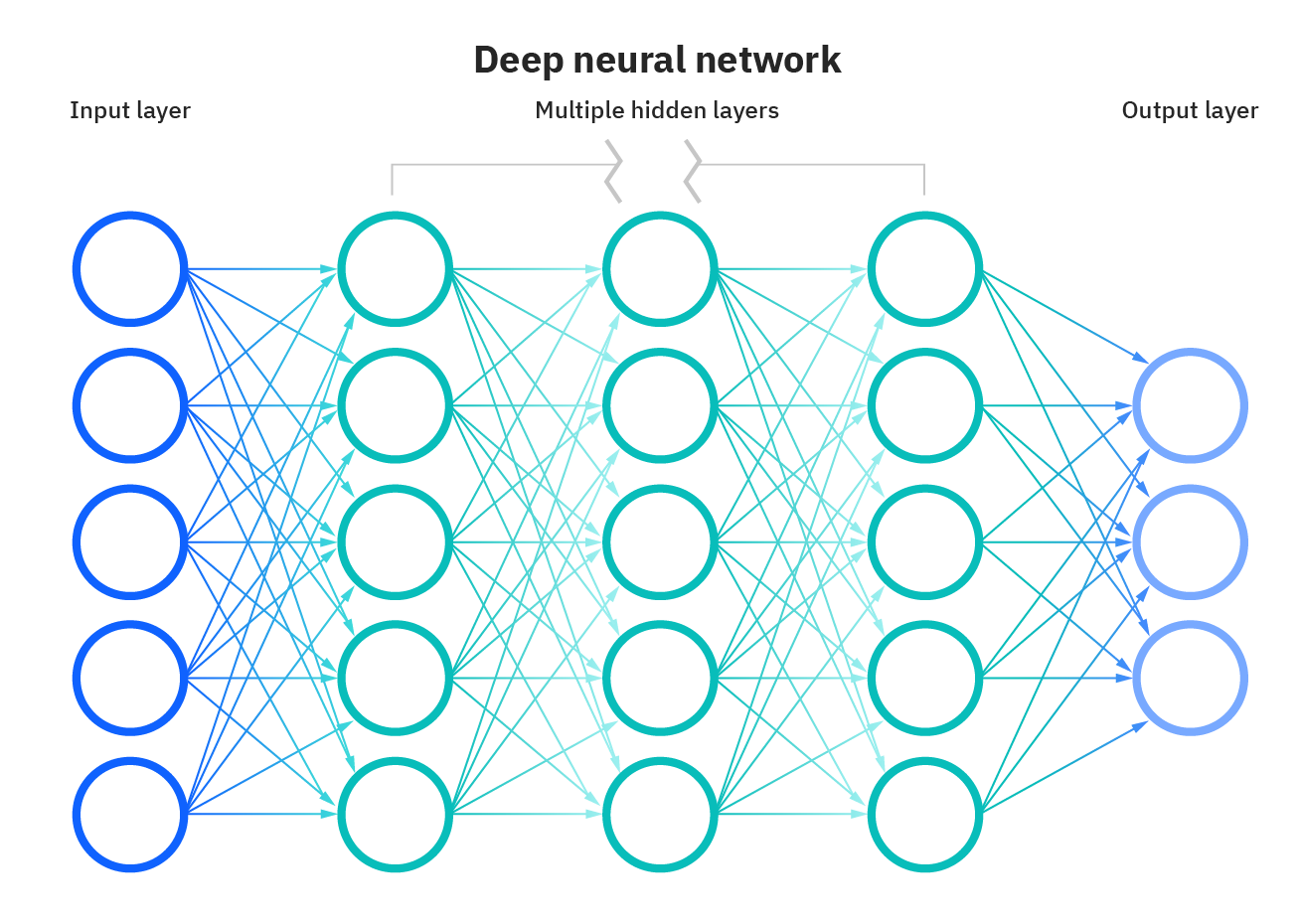
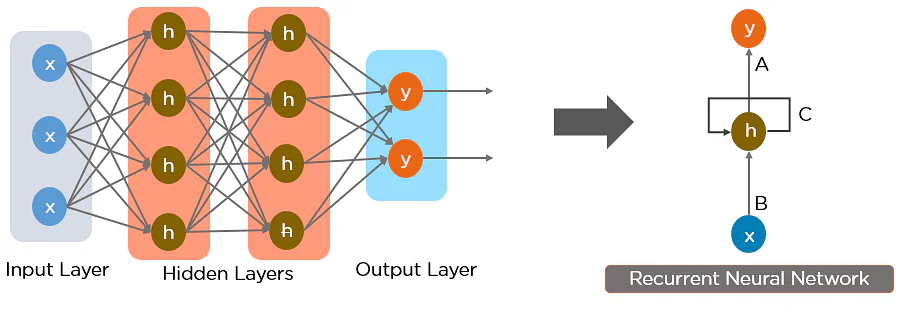
Neural Networks
Neural networks are a series of neurons that aim to recognize the underlying relationship of a given set of data. They also mimic the way a human brain operates. Neural networks have proven pattern recognition capabilities and have been utilized in many areas of bioinformatics due to their ability to cope with highly dimensional complex datasets such as those developed by protein mass spectrometry and DNA microarray experiments. Neural networks have been applied to problems such as disease classification and identification of biomarkers etc.
Types of Machine Learning Algorithms
There are three main types of machine learning algorithms; supervised, unsupervised and reinforcement learning.
Supervised Learning
Supervised learning is a machine learning approach that’s defined by its use of labeled biological datasets. These datasets are designed to train or “supervise” algorithms into classifying biological data or predicting outcomes accurately. Using labeled inputs and outputs, the model can measure its accuracy and learn over time.
Types of Supervised Learning
Supervised learning can be separated into two types of problems when data mining: classification and regression.
Supervised Learning Algorithms
Supervised algorithms include SVM, KNN, CNN, Random Forest, RNN and Regression.
Unsupervised Learning
Unsupervised learning uses machine learning algorithms to analyze and cluster unlabeled biological data sets. These algorithms discover hidden patterns in data without the need for human intervention (hence, they are “unsupervised”).
Types of Unsupervised Learning
Unsupervised learning models are used for three main tasks: clustering, association and dimensionality reduction.
Unsupervised Learning Algorithms
Unsupervised algorithms include PCA, Hierarchical Clustering, tSNE, K-means, NMF.
Reinforcement learning
Reinforcement learning supports automation by learning from the environment in which it is present. Biological entities are extremely diverse in nature and behave differently in different conditions so it’s a challenge to predict their structural and functional features from existing methods. Reinforcement learning somewhere exists between supervised and unsupervised learning and may give the solutions in such cases. Reinforcement learning is used in protein folding, health informatics, disease prediction, biomarker prediction, fragment assembly problems in NGS etc.
Top Saas Machine Learning Libraries
- Scikit-learn
- PyTorch
- Kaggle
- NLTK
- TensorFlow
Machine Learning Tools in Bioinformatics
- DeepVariant: used in genome data mining to predict common genetic variations more accurately as compared to previous classical methods.
- Atomwise Algorithms: used in drug discovery to predict molecules that can possibly interact with a specific protein with atomic precision.
- Cell Profile: used to perform analysis on biological datasets by extracting meaningful information from huge datasets such as genomes or a group of images using deep learning techniques in order to build a model based on the extracted features.
Get in touch with us and we will start your analysis right away!
